Connect compute
GPU owners expose available model-serving capacity to the network.
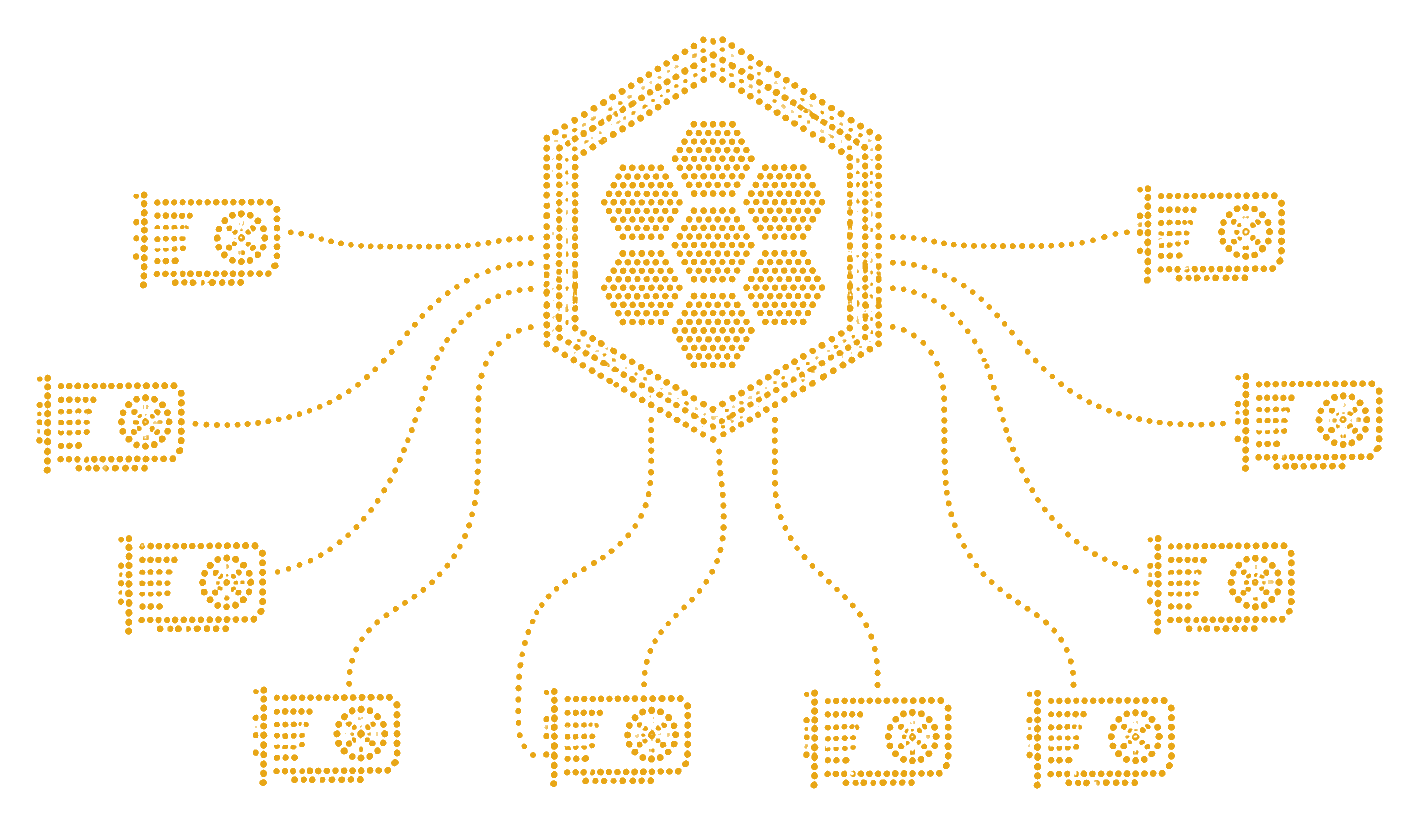
One API for distributed AI compute.
Connected GPUs become the hive. Model pools become shared capacity.
Thesis
GPU owners expose available model-serving capacity to the network.
Workers capable of serving the same model form shared capacity.
Developers call one interface instead of managing individual nodes.
Latency, availability, failures, and usage should be inspectable.
Network
Machines can come online, go offline, change load, or switch models. Honey hides the mess from developers while keeping routing visible.
Use cases
Give agents shared inference instead of tying them to one local box.
Combine workstations, lab machines, and rented GPUs behind one endpoint.
Route model calls for bots, web apps, automations, and internal tools.